Тестирование энергоэффективности и скорости вычислений видеокарт для майнинга в BOINC проектах
На момент написания статьи идет криптозима (весна 2025 года). Количество предложений видеокарт от майнеров на популярных площадках увеличивается, и сейчас неплохое время для апгрейда оборудования. Материал этой статьи будет полезен для сравнения характеристик видеокарт для майнинга в проектах распределенных вычислений на платформе BOINC.
Подробно о добровольных вычислениях и проектах можно почитать здесь: https://ru.wikipedia.org/wiki/Добровольные_вычисления
https://ru.wikipedia.org/wiki/BOINC
Характеристики графических процессоров, которые будут протестированы, приведены в таблице 1. Данные для таблицы взяты с сайта techpowerup.com, как показали эксперименты в реальности тактовая частота работы графических процессоров отличается от приведенной в открытых источниках. Также по графическому процессору CMP 90HX в таблице завышен показатель TDP, как показали замеры, энергопотребление ограничено мощностью 250 Вт. Возможно попался экземпляр с модифицированным биосом.
Таблица 1 – Характеристики графических процессоров
| Название процессора | Nvidia CMP 170HX (GA100-105F-A1) | Nvidia P102-100 (GP102-100-A1) | Nvidia 1080ti Duke (GP102-350-K1-A1) | Nvidia CMP 90HX (GA102-100-A1) |
| Архитектура | Ampere | Pascal | Pascal | Ampere |
| Технологический процесс производства, нм | 7 | 16 | 16 | 8 |
| Унифицированных шейдерных процессоров, шт | 4480 | 3200 | 3584 | 6400 |
| Текстурных блоков, шт | 280 | 200 | 224 | 200 |
| Блоков растеризации, шт | 128 | 80 | 88 | 80 |
| Потоковых мультипроцессоров, шт | 70 | 25 | 28 | 50 |
| Ядра Tensor, шт | 280 | 0 | 0 | 200 |
| Тактовая частота номинальная, МГц | 1140 | 1582 | 1481 | 1500 |
| Тактовая частота максимальная, МГц | 1410 | 1683 | 1582 | 1710 |
| Пропускная способность памяти, ГБ/с | 2900 | 440,3 | 484,4 | 760,3 |
| Производительность FP16 (половинной точности), TFLOPS | 50,530 | 0,1683 | 0,1772 | 21,89 |
| Производительность FP32 (одинарной точности), TFLOPS | 12,630 | 10,77 | 11,34 | 21,89 |
| Производительность FP64 (двойной точности), TFLOPS | 6,317 | 0,3366 | 0,3544 | 0,342 |
| Требования по теплоотводу, TDP, Вт | 250 | 250 | 250 | 320 |
Характеристики тестового стенда приведены в таблице 2.
Таблица 2 – Состав тестового стенда
| Операционная система | Microsoft Windows 10 Pro 10.0.19045.5608 (Win10 22H2 2022 Update) |
| Тип ЦП | QuadCore Intel Core i5-6600K, 3700 MHz (37 x 100) |
| Системная плата | Asus B250 Mining Expert |
| Системная память | Kingston HyperX KHX2400C14D4/16G 2шт |
| Блок питания | IBM DPS-2980AB 2980W |
Установка драйверов
В Windows видеокарты CMP 170HX и P102-100 одновременно работать с BOINC отказались, видимо это связано с тем, что для этих видеокарт драйвера находятся в разных установочных пакетах (для CMP 170HX требуется Datacenter driver for Windows).
Если вы все сделали правильно, в диспетчере устройств появится видеоадаптер NVIDIA A100.
Настройка системы охлаждения графического процессора
Ниже приводится описание, как установить драйверы для видеокарты CMP 170HX в Windows 10 Pro.
Уменьшение влияния на производительность графического процессора центрального процессора
Видеокарта CMP 170HX является урезанной версией ускорителя NVIDIA A100, однако производитель не включил отдельный драйвер в установочный пакет, и поиск драйвера на сайте nvidia ни к чему не приведет. Чтобы установить драйвер для CMP 170HX, необходимо скачать Data Center Driver for Windows с поддержкой устройств A-series. На момент написания этого обзора, самая новая версия этого драйвера 572.61-data-center-tesla-desktop-win10-win11-64bit-dch-international. Далее нужно распаковать файлы драйвера в папку (например, программой 7zip) и через диспетчер устройств указать Поиск и установка драйвера вручную
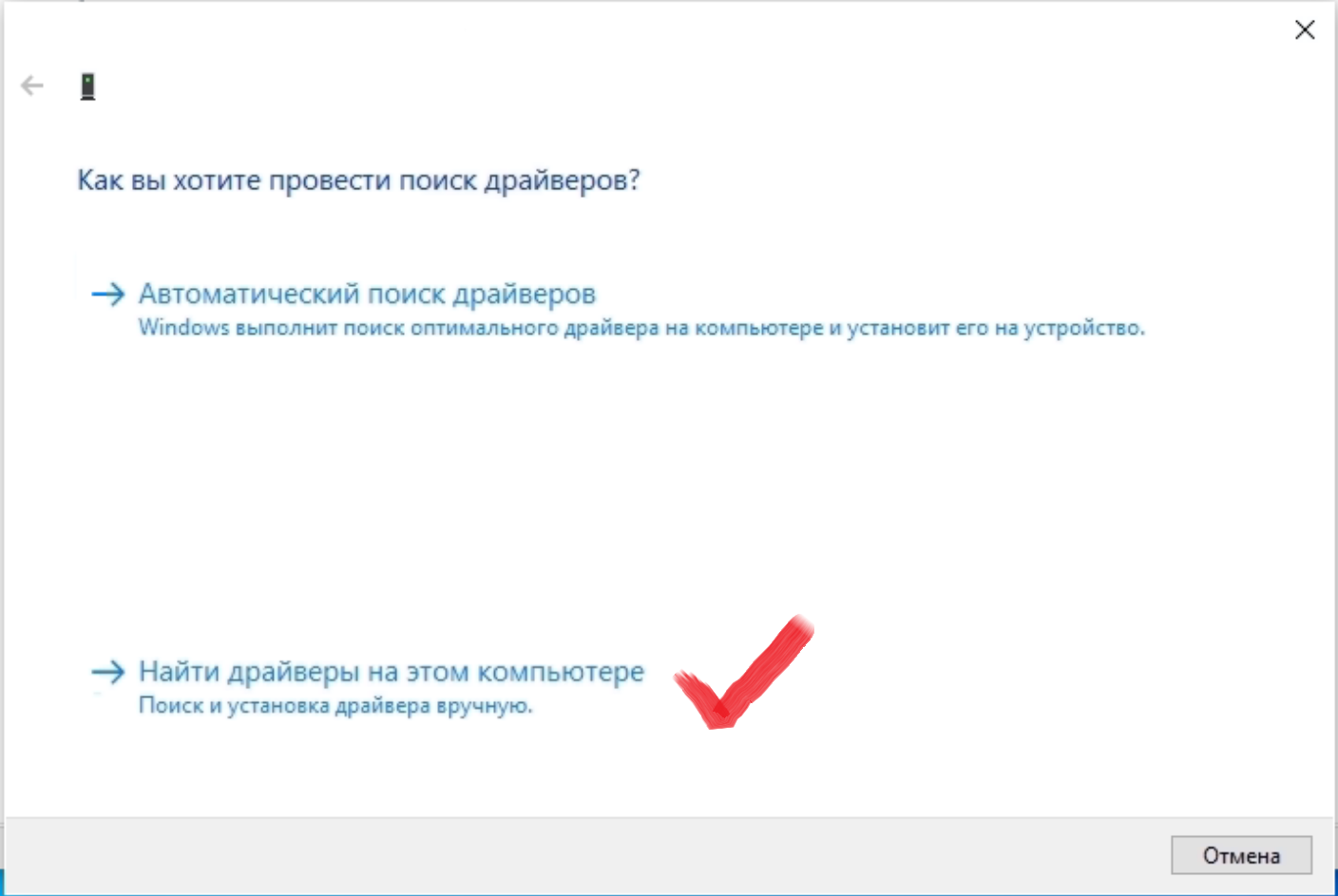
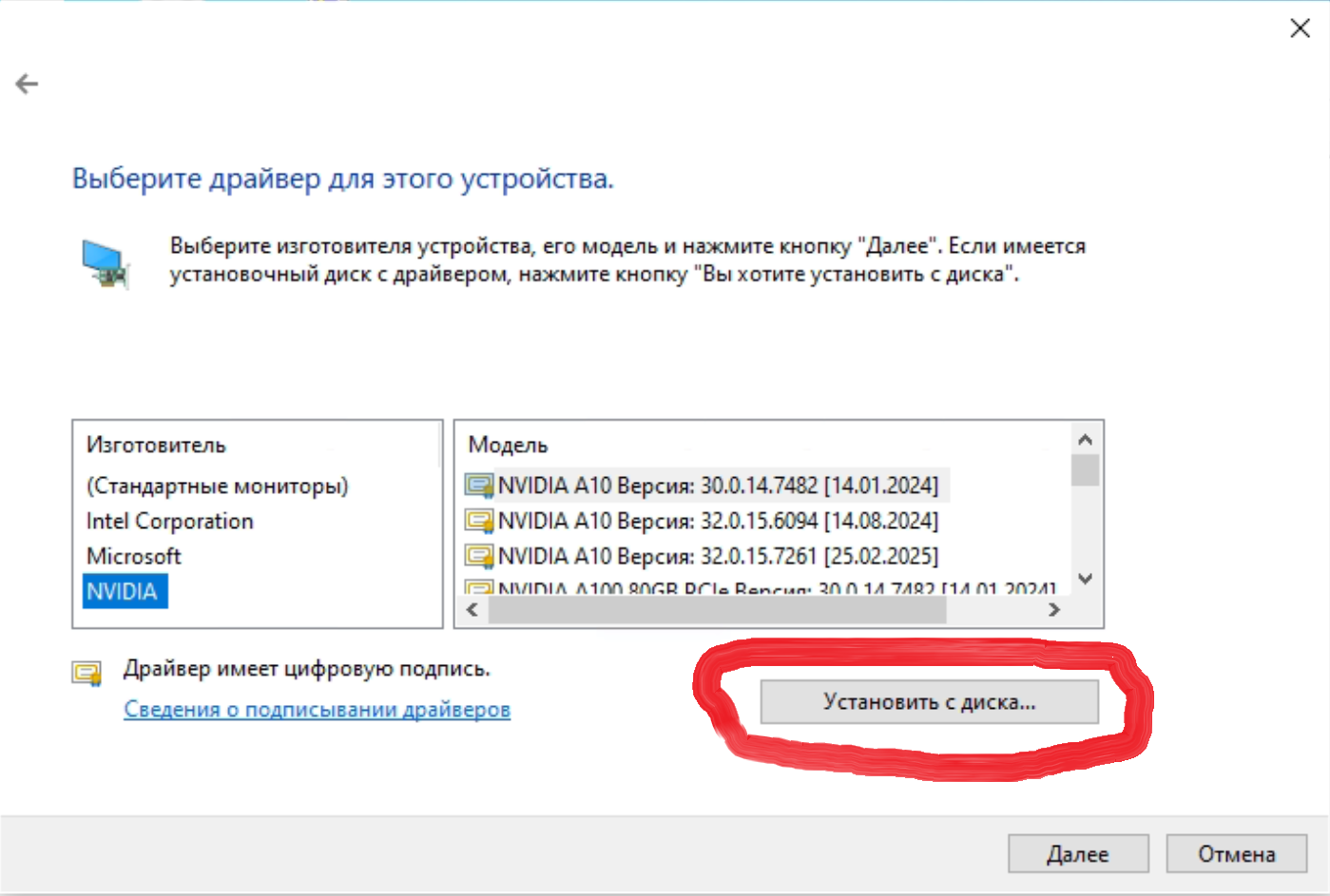
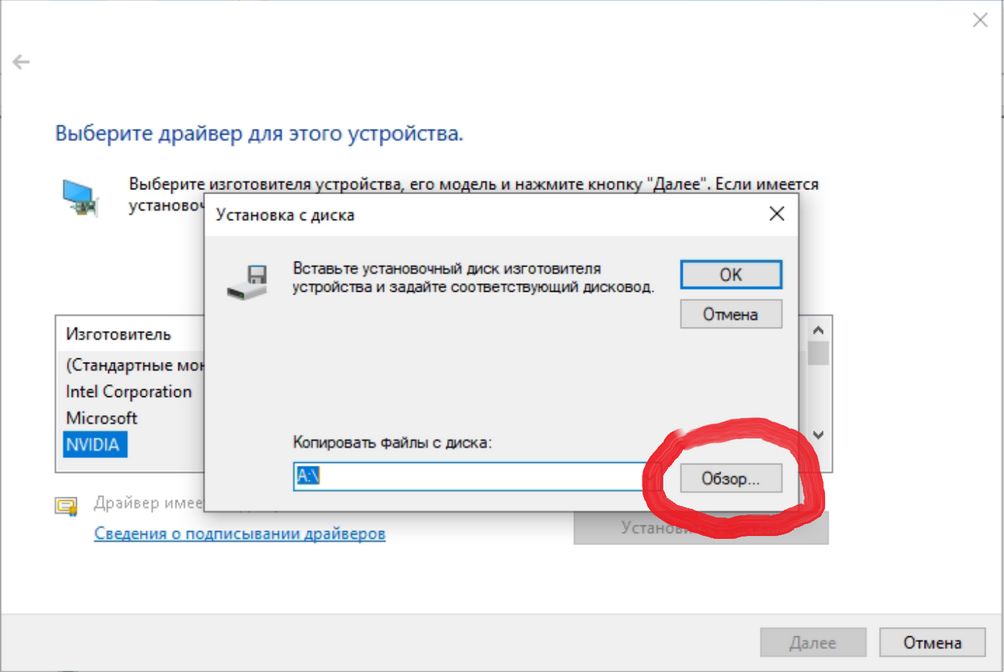{kind=link}
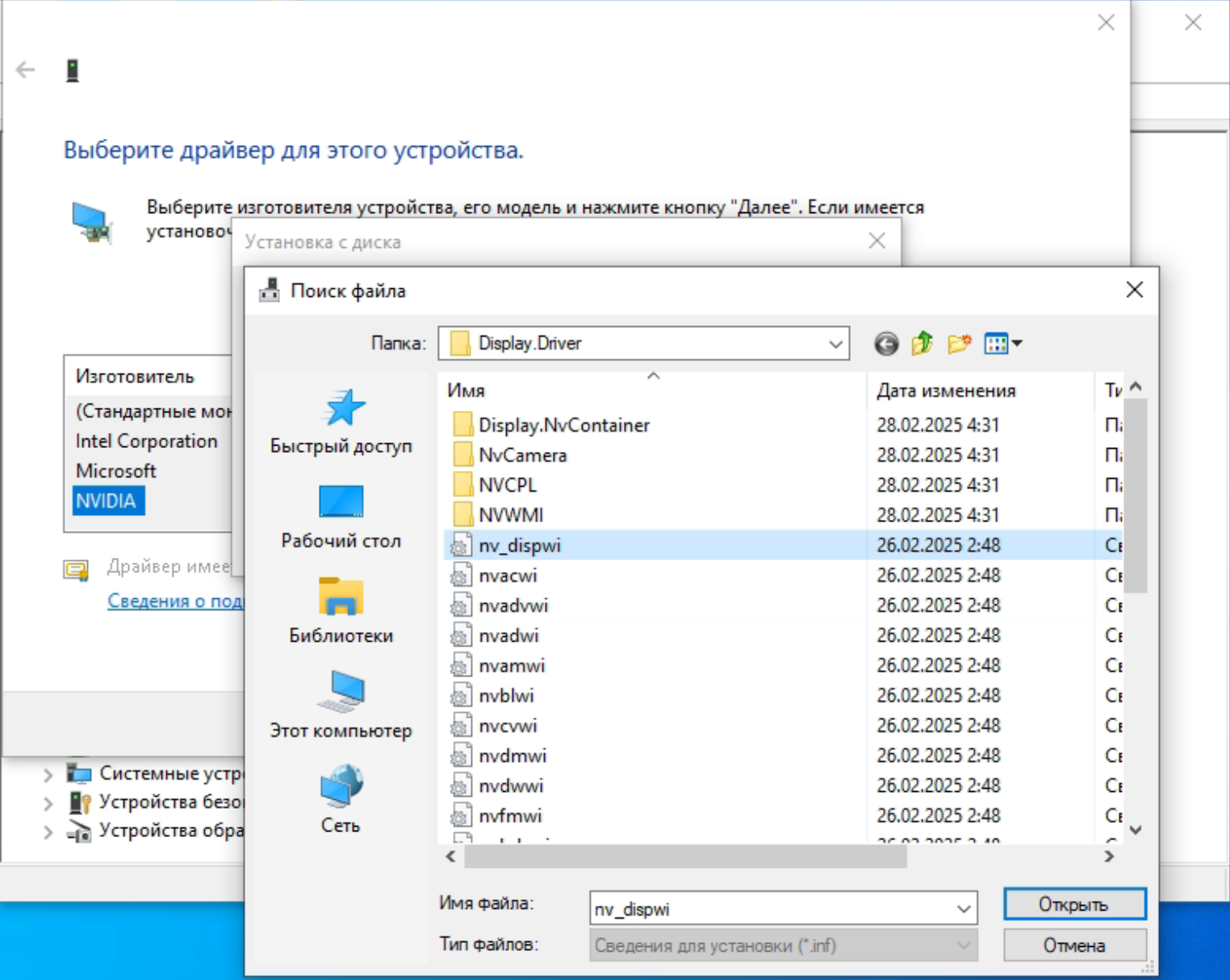
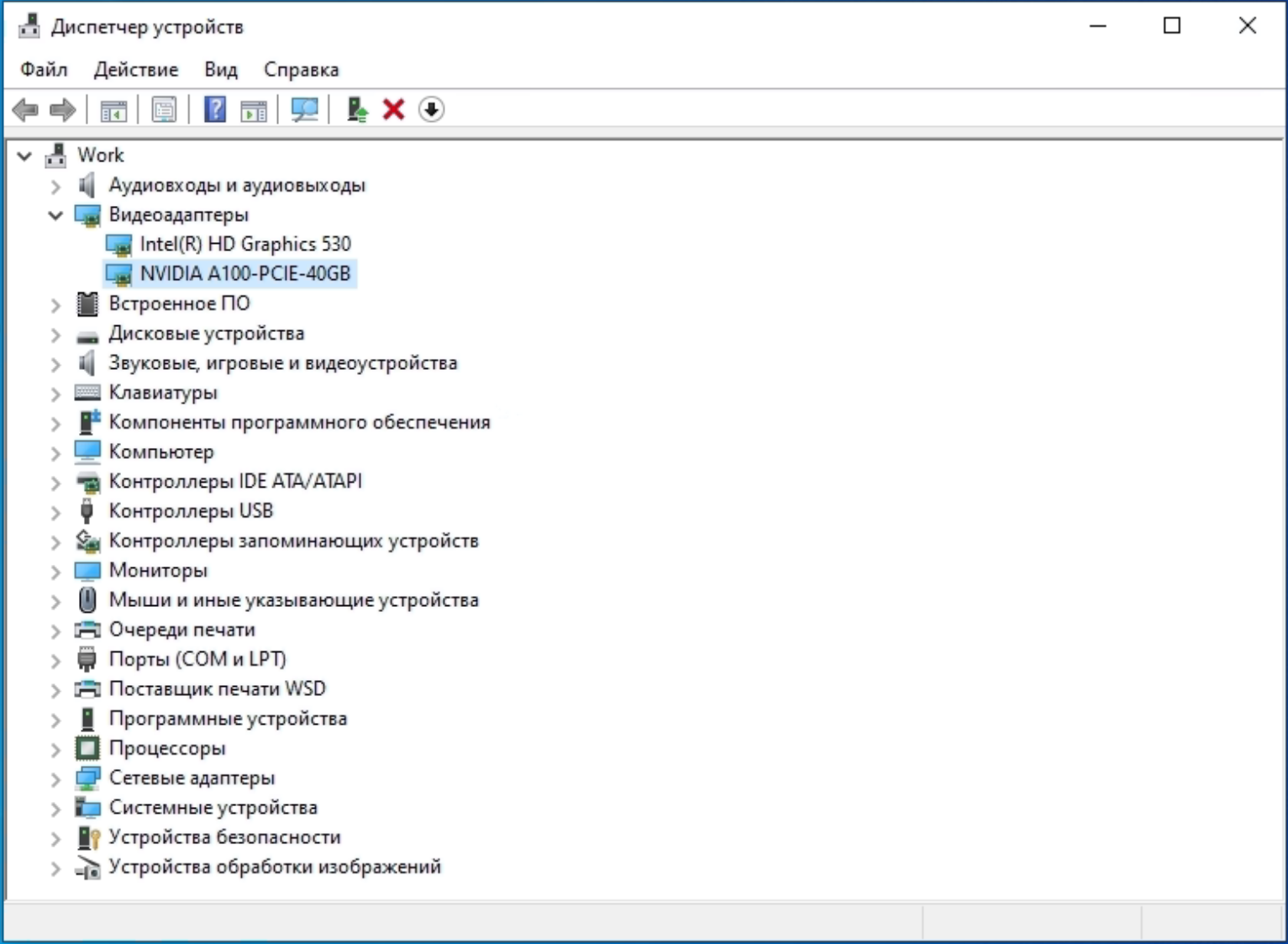
Если вы все сделали правильно, в диспетчере устройств появится видеоадаптер NVIDIA A100.
Настройка системы охлаждения графического процессора
Современные графические процессоры имеют встроенную температурную защиту от перегрева. При приближении температуры кристалла к критической, происходит динамическое изменение частоты работы процессора (частота снижается), за счет этого температура не поднимается выше. Также существует лимит по энергопотреблению, который также имеет связь с температурой кристалла. Чтобы исключить влияние температуры на производительность, удобнее всего вручную задать скорость вращения вентиляторов системы охлаждения, проверив под нагрузкой, что максимальная температура кристалла графического процессора меньше критической и тактовая частота постоянная (равна максимальной). Например, для работы CMP 170HX с максимальной производительностью, температура кристалла должна быть меньше 73 градусов. Уже про 74 градусах максимальная тактовая частота будет ниже 1410 МГц.
Уменьшение влияния на производительность графического процессора центрального процессора
Различные задачи BOINC нагружают центральный процессор по-разному. При оценке производительности графического процессора (GPU), нужно убедиться, что центральный процессор (CPU) не является узким местом вычислительной системы. При работе приложений BOINC, использующих видеокарту, загрузка центрального процессора не должна быть 100%. Особенно это актуально если в системе несколько видеокарт и проект активно использует ресурсы центрального процессора. Например, при использовании тестового стенда и 5 видеокарт Zotac P102-100 для расчетов заданий проекта Einstein@Home, время выполнения задания выше на 50%, из-за перегрузки центрального процессора. При использовании 3-х видеокарт Zotac P102-100, в проекте Einstein@Home перегрузки процессора Intel Core i5-6600K уже не происходит, как результат - производительность вычислительной системы с тремя видеокартами выше, чем с пятью. Если центральный процессор не является узким местом вычислительной системы, время выполнения задания и время ЦП в статистике задания должны быть примерно равны (для All-Sky Gravitational Wave search on O3), и загрузка процессора меньше 100%.
| CMP170hX, GPU 1410, Memory 1458, i5-6600, версия драйвера 572.61 | ||||||||||||
| Проект | Приложение | Задание | Объем вычислений, GFLOPs | Затрачено времени, с | Потребление GPU, Вт | Использование GPU, % | Использование CPU, % | Cobblestones за задание | Квт*ч на задание | Cobblestones/с | Cobblestones/ч | Cobblestones/Квт*ч |
| Einstein@Home | All-Sky Gravitational Wave search on O3 1.16 (GW-opencl-nvidia-3) | h1_0201.80_O3aLC01Cl1In0 __O3ASBu_202.00Hz_68521 | 1 440 000 | 1845 | 102,4 | 73,9 | 36,0 | 20000 | 0,052480 | 10,84 | 39024 | 381098 |
| PrimeGrid | Genefer 17 Mega 4.06 (OCLcudaGFN17MEGA) | genefer17mega_219485926 | 29 688 | 202 | 109,2 | 83,0 | 18,1 | 510,49 | 0,006125 | 2,53 | 9098 | 83351 |
| PrimeGrid | Genefer 18 4.04 (OCLcudaGFN18) | genefer18_225373750 | 110 235 | 545 | 143,0 | 91,5 | 10,4 | 1895,17 | 0,021644 | 3,48 | 12519 | 87562 |
| PrimeGrid | Genefer 19 4.04 (OCLcudaGFN19) | genefer19_227978953 | 484 656 | 1691 | 187,9 | 97,6 | 8,6 | 8333 | 0,088253 | 4,93 | 17740 | 94422 |
| PrimeGrid | Genefer 20 4.04 (OCLcudaGFN20) | genefer20_216644352 | 1 855 379 | 5607 | 225,33 | 98,7 | 6,6 | 35090 | 0,350945 | 6,26 | 22530 | 99987 |
| PrimeGrid | Genefer 21 4.04 (OCLcudaGFN) | genefer21_195292090 | 8 373 269 | 22049 | 245,23 | 98,8 | 4,5 | 172767 | 1,501957 | 7,84 | 28208 | 115028 |
| P102-100 Zotac, GPU 1860, Memory 5508, i5-6600k, версия драйвера 384.74 | ||||||||||||
| Проект | Приложение | Задание | Объем вычислений, GFLOPs | Затрачено времени, с | Потребление GPU*, Вт | Использование GPU, % | Использование CPU, % | Cobblestones за задание | Квт*ч на задание | Cobblestones/с | Cobblestones/ч | Cobblestones/Квт*ч |
| Einstein@Home | All-Sky Gravitational Wave search on O3 1.16 (GW-opencl-nvidia-3) | h1_0201.80_O3aLC01Cl1In0__O3ASBu_202.00Hz_35696 | 1 440 000 | 3478 | 153,8 | 66,6 | 32,6 | 20000 | 0,148550 | 5,75 | 20702 | 134635 |
| PrimeGrid | Genefer 17 Mega 4.06 (OCLcudaGFN17MEGA) | genefer17mega_219516315 | 29 689 | 514 | 180,3 | 81,6 | 11,8 | 510,49 | 0,025737 | 0,99 | 3575 | 19835 |
| PrimeGrid | Genefer 18 4.04 (OCLcudaGFN18) | genefer18_225374024 | 110 235 | 1576 | 226,1 | 93,9 | 10,6 | 1895,17 | 0,098976 | 1,20 | 4329 | 19148 |
| PrimeGrid | Genefer 19 4.04 (OCLcudaGFN19) | genefer19_227981822 | 484 694 | 5341 | 245,0 | 96,3 | 6,4 | 8333 | 0,363546 | 1,56 | 5617 | 22921 |
| PrimeGrid | Genefer 20 4.04 (OCLcudaGFN20) | genefer20_216645211 | 1 855 379 | 17431 | 245,3 | 97,3 | 5,8 | 35090 | 1,187618 | 2,01 | 7247 | 29547 |
* У P102-100 отсутствует измерение потребляемой мощности с помощью Afterburner, соответственно эти данные заполнялись с помощью пересчета % мощности GPU и значения TDP в потребляемую мощность. Так как величина TDP не является максимальным теоретическим тепловыделением процессора, то полученные при пересчете значения не будут точными. Для 1080ti есть данные и по потребляемой мощности в Ваттах и по мощности GPU в %. Мощность, измеренная в Ваттах примерно на 11-12% больше чем рассчитанная мощность (Мощность GPU в % умножить на TDP и разделить на 100%). Для точного измерения потребляемой мощности требуются внешние приборы, эта задача выходит за рамки настоящего исследования.
| 1080ti Duke, GPU 1936, Memory 5005, i5-6600k версия драйвера 560.94 | ||||||||||||
| Проект | Приложение | Задание | Объем вычислений, GFLOPs | Затрачено времени, с | Потребление GPU, Вт | Использование GPU, % | Использование CPU, % | Cobblestones за задание | Квт*ч на задание | Cobblestones/с | Cobblestones/ч | Cobblestones/Квт*ч |
| Einstein@Home | All-Sky Gravitational Wave search on O3 1.16 (GW-opencl-nvidia-3) | h1_0202.80_O3aLC01Cl1In0__O3ASBu_203.00Hz_65384 | 1 440 000 | 3140 | 146,0 | 66,6 | 31,8 | 20000 | 0,127351 | 6,37 | 22930 | 157046 |
| PrimeGrid | Genefer 17 Mega 4.06 (OCLcudaGFN17MEGA) | genefer17mega_219410381 | 29 688 | 512 | 178,9 | 76,2 | 21,7 | 510,49 | 0,025441 | 1,00 | 3589 | 20066 |
| 90HX, GPU 1890-1575, Memory 9501, i5-6600k версия драйвера 560.94 bios 94.02.74.00.01 лимит мощности 250 Вт | ||||||||||||
| Проект | Приложение | Задание | Объем вычислений, GFLOPs | Затрачено времени, с | Потребление GPU, Вт | Использование GPU, % | Использование CPU, % | Cobblestones за задание | Квт*ч на задание | Cobblestones/с | Cobblestones/ч | Cobblestones/Квт*ч |
| Einstein@Home | All-Sky Gravitational Wave search on O3 1.16 (GW-opencl-nvidia-3) | h1_0202.80_O3aLC01Cl1In0__O3ASBu_203.00Hz_65386 | 1 440 000 | 2088 | 180,1 | 80,0 | 34,3 | 20000 | 0,104479 | 9,58 | 34483 | 191426 |
| PrimeGrid | Genefer 17 Mega 4.06 (OCLcudaGFN17MEGA) | genefer17mega_228480484 | 29 691 | 224 | 211,1 | 85,4 | 14,3 | 510,49 | 0,013137 | 2,28 | 8196 | 38821 |
| PrimeGrid | Genefer 21 4.04 (OCLcudaGFN) | genefer21_229505960c | 130 856 | 667 | 217,8 | 94,6 | 9,9 | 2700,2 | 0,040349 | 4,05 | 14574 | 66922 |
| PrimeGrid | Genefer 19 4.04 (OCLcudaGFN19) | genefer19_227986516 | 484 757 | 2524 | 246,1 | 99,1 | 8,1 | 8335 | 0,172519 | 3,30 | 11888 | 68910 |
| PrimeGrid | Genefer 20 4.04 (OCLcudaGFN20) | genefer20_216646063 | 1 855 679 | 8880 | 247,1 | 99,2 | 6,3 | 35100 | 0,609426 | 3,95 | 14230 | 57595 |
Затраты энергии на выполнение задания на CMP 170HX в 3,9 раза меньше чем у графических процессоров GeForce 10 серии. Скорость вычислений CMP 170HX в различных приложениях BOINC выше в 3,1 раза по сравнению с 1080ti и P102-100.
Затраты энергии на выполнение задания CMP 90HX в 1,9 раза меньшее чем у графических процессоров GeForce 10 серии Скорость вычислений CMP 90HX в различных приложениях BOINC выше в 2 раза по сравнению с 1080ti и P102-100.
На сайте проекта PrimeGrid имеется информация о относительной скорости графических процессоров (вычисляется автоматически на основе присланных результатов) https://www.primegrid.com/gpu_list.php#GFN20. К сожалению, там нет информации по графическим процессорам для майнинга. Приняв допущение, что производительность P102-100 примерно равна производительности 1080ti, получаем следующий рейтинг по относительной скорости (для задач Genefer 20 4.04 (OCLcudaGFN20).
| № п.п. | Относительная скорость | Модель | Время вычисления задания объемом 1855379 GFLOPS, с |
| 1 | 1,000 | NVIDIA GeForce RTX 4090 | |
| 2 | 0,795 | NVIDIA GeForce RTX 4080 | |
| 3 | 0,620 | NVIDIA GeForce RTX 4070 Ti SUPER | |
| 4 | 0,619 | NVIDIA GeForce RTX 4070 Ti | |
| 5 | 0,526 | NVIDIA GeForce RTX 4070 SUPER | |
| 6 | 0,444 | NVIDIA CMP 170HX | 5607 |
| 7 | 0,391 | NVIDIA GeForce RTX 4060 Ti | |
| 8 | 0,358 | NVIDIA GeForce RTX 4070 Laptop GPU | |
| 9 | 0,346 | NVIDIA GeForce RTX 3080 | |
| 10 | 0,333 | NVIDIA L4 | |
| 11 | 0,280 | NVIDIA CMP 90HX | 8880 |
| 12 | 0,263 | NVIDIA GeForce RTX 4060 | |
| 13 | 0,260 | NVIDIA GeForce RTX 2080 Ti | |
| 14 | 0,255 | NVIDIA GeForce RTX 3070 Ti | |
| 15 | 0,235 | Tesla V100-FHHL-16GB | |
| 16 | 0,218 | NVIDIA GeForce RTX 3070 | |
| 17 | 0,209 | NVIDIA GeForce RTX 3060 Ti | |
| 18 | 0,186 | NVIDIA TITAN V | |
| 19 | 0,183 | NVIDIA GeForce RTX 2060 SUPER | |
| 20 | 0,162 | NVIDIA GeForce RTX 3060 | |
| 21 | 0,144 | NVIDIA RTX A4000 | |
| 22 | 0,143 | NVIDIA P102-100 | 17431 |
| 23 | 0,143 | NVIDIA GeForce GTX 1080 Ti | |
| 24 | 0,141 | NVIDIA GeForce RTX 3060 Laptop GPU | |
| 25 | 0,139 | NVIDIA GeForce RTX 2060 | |
| 26 | 0,132 | Tesla P40 | |
| 27 | 0,124 | NVIDIA GeForce GTX 1660 SUPER | |
| 28 | 0,122 | NVIDIA GeForce GTX 1660 Ti | |
| 29 | 0,095 | NVIDIA GeForce RTX 3050 | |
| 30 | 0,077 | NVIDIA GeForce GTX 1060 6GB | |
| 31 | 0,064 | NVIDIA GeForce GTX 1060 3GB | |
| 32 | 0,058 | NVIDIA GeForce GTX 1650 |
В рейтинге CMP 90HX заметно ниже NVIDIA GeForce RTX 3080, разница в 23% объясняется уменьшением лимита потребляемой мощности до 250 Вт, скорее всего при одинаковом лимите энергопотребления, время вычисления заданий тоже будет одинаковым.
Графический процессор CMP 170HX также занял достойное место в рейтинге. При вычислениях задач Genefer 20 4.04 потребляемая мощность практически равна значению TDP. У топа из рейтинга - GeForce RTX 4090 TDP равно 450 Вт, у CMP 170HX измеренное потребление – 225 Вт. Соответственно, если сравнить скорость при одинаковом энергопотреблении, производительность двух ускорителей CMP 170HX будет ниже на 12% производительности одной карты GeForce RTX 4090. Тут нужно отметить, что 170HX выпускается по техпроцессу 7 нм, а RTX 4090 по техпроцессу 5нм.